execo user guide¶
In this user guide, the code can be executed from python source files,
but it can also be run interactively in a python shell, such as
ipython, which is very convenient to inspect the execo objects.
Installation¶
Prerequisites: see corresponding section in Readme / documentation for the execo package.
In this tutorial it is shown how to install execo in subdirectory
.local/ of your home, allowing installation on computers where you
are not root or when you don’t want to mix manually installed packages
with packages managed by your distribution package manager.
Install from a release tar.gz package:
$ wget https://gitlab.inria.fr/mimbert/execo/-/package_files/[...]/download -O execo-2.7.tar.gz $ tar xzf execo-2.7.tar.gz $ cd execo-2.7/ $ python setup.py install --user
Or install from source repository if you want the very latest version:
$ git clone https://gitlab.inria.fr/mimbert/execo.git $ cd execo $ python setup.py install --user
Or install with
piporeasy_install:$ pip install --user execo
or:
$ easy_install --user execo
Or install from debian package:
$ dpkg -i python-execo_2.7_all.deb
Configuration¶
Execo reads configuration file ~/.execo.conf.py. A sample
configuration file execo.conf.py.sample is created in execo source
package directory when execo is built. This file can be used as a
canvas to overide some particular configuration variables. See
detailed documentation in Configuration, Grid5000
Configuration and
The perfect grid5000 connection configuration.
execo generalities¶
One of the execo paradigms is that concurrent remote operations will necessarily fail (especially when their number increases). Such conditions in execo are handled as metadata associated with the process or actions objects, so the programming flow does not need to continuously check for return codes or catch exceptions.
Thus, when, for example, several remote processes are run and some of them fail, there is no error nor interruption of the program. The failed processes record the error (there are actually two kinds of errors: the process returning a value != 0, or an operating system error, for situations where the process executable was not found). When a program tries to write to the stdin of several processes, if some writes fail (because of an invalid stdin file descriptor, for example), same thing: this is recorded and the program keeps executing.
The default behavior on every kind of error, is to log the error, but some process flags can instruct execo to not log such errors (in cases where we, programmer, do “know” that the error is “normal”).
Process and Action instances have an ok meta-flag which summarizes
their various state flags. There are also some process flags which can
instruct particular processes or actions to ignore some flags when
computing if the process is ok. For example, we can run a
particular executable whose return value is always different from 0,
though this is not an error condition. We can instruct the process to
ignore this when computing its ok meta-flag.
As many process and action methods do not need to return a status,
instead method chaining is widely used in execo: most process or
actions methods return the object itself (self). For example,
process.run() is the equivalent of (and can be written as)
process.start().wait(). Method chaining can provide a more fluent
syntax in some situations.
execo¶
Core module. Handles launching of several operating system level processes in parallel and controlling them asynchronously. Handles remote executions and file copies with ssh/scp and taktuk.
- Standalone processes:
execo.process.Process,execo.process.SshProcess - Parallel processes:
execo.action.Action
Processes¶
execo.process.Process: abstraction of an operating system process. Fine grain asynchronous lifecycle handling:- start, wait, kill
- stdout, stderr, error, pid, exit code
- start date, end date
- timeout handling
- callbacks
- shell; pty
execo.process.SshProcess: Same thing but through ssh. Additional parameter: Host, ConnectionParams- Host: abstraction of a remote host: address, user, keyfile, port
- ConnectionParams: connection parameters, ssh options, ssh path, keyfile, port, user, etc.
execo.process.Serialandexeco.process.SerialSsh: local or remote (over ssh) connection to a serial port.execo.process.PortForwarder: port forwarder process
Process examples¶
Local process¶
List all files in the root directory:
from execo import *
process = Process("ls /")
process.run()
print("process:\n%s" + str(process))
print("process stdout:\n" + process.stdout)
print("process stderr:\n" + process.stderr)
The ls process was directly spawned, not using a subshell. Set
process property shell to True if a full shell environment
is needed (e.g. to expand environment variables or to use pipes). To
find all files in /tmp belonging to me:
process = Process("find /tmp -user $USERNAME", shell = True)
process.run()
Here a warning log was probably displayed, because if you are not
root, there are probably some directories in /tmp that find
could not visit (lack of permissions), find does not return 0 in
this case. The default behavior of execo is to issue warning logs when
processes are in error, do not return 0, or timeout. If needed we can
instruct execo to stop logging the exit code by setting process property
nolog_exit_code to True. In this case, no log will be issued
but the process will still be considered in error from execo’s point
of view. You can also instruct execo to ignore the exit code by
setting process property ignore_exit_code to True.
Remote process over ssh¶
On one host host1 Start an execo.process.SshProcess process_A
running a listening netcat, then on another host
host2 start an execo.process.SshProcess process_B running netcat
sender, then wait for process_B termination, then kill
process_A:
from execo import *
with SshProcess("nc -lvp 6543", "<host1>").start() as receiver:
sleep(1)
sender = SshProcess("echo 'hi there!' | nc -q 0 <host1> 6543", "<host2>").run()
receiver.wait()
print(receiver.stdout)
This example shows the asynchronous control of processes: while a process is running (the netcat receiver), the code can do something else (run the netcat sender), and later get back control of the first process, waiting for it (it could also kill it).
The process class hierarchy provides python context managers, so at
the end of a block of code starting with with <process> as ...,
the process will automatically be killed. Note that as with many
things in execo, this kill is asynchronous, so when the program gets
out the with block, the kill signal is issued, but the process may not
be properly killed yet when executing the next instruction. So if you
need to be sure that the process has finished, you need to wait for
it, hence the line receiver.wait(), to make sure that every output
of the receiver process has been caught before printing its stdout.
This example also illustrates method chaining:
- the
start()method can be immediately called on the instanciated sender process within thewithstatment, becauseprocess.start()return the process itself. - the sender process is instanciated,
run()is called on it, and the result can be affected to the sender variable because run() returns the object itself.
In this example, We sleep for 1 second after starting the server to
make sure that it is ready to receive incoming connections (without
this sleep, it may work, perhaps most of the time, because netcat is
fast, but we can’t be sure). A better way to make sure the server is
ready is to scan its verbose output (we add option -v to netcat
receiver):
from execo import *
with SshProcess("nc -vlp 6543", "<host1>").start() as receiver:
receiver.expect("^[Ll]istening on")
sender = SshProcess("echo 'hi there!' | nc -q 0 <host1> 6543", "<host2>").run()
receiver.wait()
print(receiver.stdout)
Of course, this kind of code only works if you are sure that the
version of netcat which is installed on <host1> is the one you
expect, which outputs the string listening on ... on its standard
output when in verbose mode and when its socket is listening (on
debian, you need nc.traditional)
Interaction with processes: writing to a process stdin, expecting from a process stdout, on a remote serial port over ssh¶
This example shows automation of an interactive login on a serial
console connected via an usb serial adapter to a remote host. It makes
use of the write method of processes, which allows printing to
processes, and of the expect method of processes, which scans and
waits process output for regular expressions:
from execo import *
prompt = '^~ #\s*$'
with SerialSsh("<host>", "/dev/ttyUSB1", 115200).start() as serial:
print(file=serial)
serial.expect('^\w login:\s*$')
print("<login>", file=serial)
serial.expect('^Password:\s*$')
print("<password>", file=serial)
serial.expect(prompt)
print("<command>", file=serial)
Actions¶
execo.action.Action: abstraction of a set of parallel Process. Asynchronous lifecycle handling:- start, kill, wait
- access to individual Process
- callbacks
- timeout
- errors
execo.action.Local: A set of parallel local Processexeco.action.Remote: A set of parallel remote SshProcessexeco.action.TaktukRemote: Same as Remote but using taktuk instead of plain sshexeco.action.Put,execo.action.Get: send files or get files in parallel to/from remote hostsexeco.action.TaktukPut,execo.action.TaktukGet: same using taktukexeco.report.Report: aggregates the results of several Action and pretty-prints summary reportsexeco.action.ChainPut: efficient broadcast (copy) of big files to high number of hostsexeco.action.RemoteSerial: A set of parallel connections to remote serial ports over ssh.
Remote example¶
Run a netcat client and server simultaneously on two hosts, to generate traffic in both directions:
from execo import *
hosts = [ "<host1>", "<host2>" ]
targets = list(reversed(hosts))
servers = Remote("nc -l -p 6543 > /dev/null", hosts)
clients = Remote("dd if=/dev/zero bs=50000 count=125 | nc -q 0 {{targets}} 6543", hosts)
with servers.start():
sleep(1)
clients.run()
servers.wait()
print(Report([ servers, clients ]).to_string())
for s in servers.processes + clients.processes:
print("%s\nstdout:\n%s\nstderr:\n%s" % (s, s.stdout, s.stderr))
The netcat command line on clients shows the usage of substitutions: In the command line given for Remote and in pathes given to Get, Put, patterns are automatically substituted:
- all occurences of the literal string
{{{host}}}are substituted by the address of the Host to which execo connects to. - all occurences of
{{<expression>}}are substituted in the following way:<expression>must be a python expression, which will be evaluated in the context (globals and locals) where the expression is declared, and which must return a sequence.{{<expression>}}will be replaced by<expression>[index % len(<expression>)]. In short, it is a mapping between the sequence of command lines run on the hosts and the sequence<expression>. See substitutions for Remote, TaktukRemote, Get, Put.
Interaction with remotes: writing processes stdin, expecting from stdout, on several remote serial port over ssh¶
This example shows the automation of an
interactive login on several serial consoles connected to usb serial
adapters on a set of remote host. It makes use of the write method of
actions, which allows printing to actions, and of the expect
method of actions, which scans and waits process output for regular
expressions:
from execo import *
prompt = '^~ #\s*$'
with RemoteSerial(<list_of_hosts>, "/dev/ttyUSB1", 115200).start() as serial_ports:
print(file=serial_ports)
serial_ports.expect('^\w login:\s*$')
print("<login>", file=serial_ports)
serial_ports.expect('^Password:\s*$')
print("<password>", file=serial_ports)
serial_ports.expect(prompt)
print("<command>", file=serial_ports)
It is almost identical to the remote serial process example, except that it handles several remote serial ports in parallel.
execo_g5k¶
A layer built on top of execo. It’s purpose is to provide a convenient API to use Grid5000 services:
- oar
- oarsub, oardel
- get current oar jobs
- wait oar job start, get oar job nodes
- oargrid
- oargridsub, oargriddel
- get current oargrid jobs
- wait oargrid job start, get oargrid job nodes
- kadeploy3
- deploy: clever kadeploy: automatically avoids to deploy already deployed nodes, handles retries on top of kadeploy, callbacks to allow dynamically deciding when we have enough nodes (even for complex topologies)
- Grid5000 API:
- list hosts, clusters, sites and network equipments
- get the cluster of a host, the site of a cluster, the network equipments of a
- site, a cluster or a host
- get API attributes from hosts, clusters, sites, network equipments
- all of this in a secure way: even when used from outside Grid5000, there is no need to put Grid5000 API password in clear in scripts, password can be stored in the desktop environment keyring if available.
- a local disk is created in $HOME/.execo/g5k_api_cache
- planning: advanced interaction with oar scheduler: allows getting the full planning of resources on grid5000, as well as finding time slots where resources are available.
- topology: use grid5000 Network API to generate a networkx graph of the platform, with simple graphical export.
To use execo on grid5000, you need to install it inside grid5000, for example on a frontend. execo dependencies are installed on grid5000 frontends. (Note: to use execo_g5k from outside Grid5000, see Use execo from outside Grid5000)
oarsub example¶
Run iperf servers on a group of 4 hosts on one cluster, and iperf clients on a group of 4 hosts on another cluster. Each client targets a different server. We get nodes with an OAR submissions, and delete the OAR job afterwards:
from execo import *
from execo_g5k import *
import itertools
[(jobid, site)] = oarsub([
( OarSubmission(resources = "/cluster=2/nodes=4"), "nancy")
])
if jobid:
try:
nodes = []
wait_oar_job_start(jobid, site)
nodes = get_oar_job_nodes(jobid, site)
# group nodes by cluster
sources, targets = [ list(n) for c, n in itertools.groupby(
sorted(nodes, key=get_host_cluster),
get_host_cluster) ]
servers = Remote("iperf -s",
targets,
connection_params = default_oarsh_oarcp_params)
clients = Remote("iperf -c {{[t.address for t in targets]}}",
sources,
connection_params = default_oarsh_oarcp_params)
with servers.start():
sleep(1)
clients.run()
servers.wait()
print(Report([ servers, clients ]).to_string())
for index, p in enumerate(clients.processes):
print("client %s -> server %s - stdout:" % (p.host.address,
targets[index].address))
print(p.stdout)
finally:
oardel([(jobid, site)])
This example shows how python try / finally construct can be used to make sure reserved resources are always released at the end of the job. It also shows how we can use python tools (itertools.groupby) to group hosts by cluster, to build an experiment topology, then use this topology with execo substitutions. The exit code of the servers is ignored (not counted as an error and not logged) because it is normal that they are killed at the end (thus they always have a non-zero exit code).
execo_g5k.api_utils¶
This module provides various useful function which deal with the Grid5000 API.
For example, to work interactively on all grid5000 frontends at the same time: Here we create a directory, copy a file inside it, then delete the directory, on all frontends simultaneously:
from execo import *
from execo_g5k import *
sites = get_g5k_sites()
Remote("mkdir -p execo_tutorial/",
sites,
connection_params = default_frontend_connection_params).run()
Put(sites,
["~/.profile"],
"execo_tutorial/",
connection_params = default_frontend_connection_params).run()
Remote("rm -r execo_tutorial/",
sites,
connection_params = default_frontend_connection_params).run()
If ssh proxycommand and execo configuration are configured as described in Use execo from outside Grid5000, this example can be run from outside grid5000.
Here is another example of a one-liner to list the measured flops of each cluster:
for cluster in get_g5k_clusters(): print(f"{cluster} {get_host_attributes(Host(cluster + '-1')).get('performance')}")
Other usage examples¶
Check CPU performance settings of each Grid5000 clusters¶
In this example, the planning module is used to automatically compute how many resources we can get on Grid5000.
This code reserves one node on each grid5000 cluster immediately available, for a 10 minutes job. Then it waits for the job start and retrieves the list of nodes. Then, it remotely executes shell commands to:
- get the current cpufreq governor for each core (p-states)
- detect if hyperthreading is on
- detect if c-states are on
- detect if turboboost is on
(see https://www.grid5000.fr/mediawiki/index.php/CPU_parameters_in_Grid5000)
To each remote process, a stdout_handler is added which directs its stdout to a file called <nodename>.out on localhost:
from execo import *
from execo_g5k import *
logger.info("compute resources to reserve")
blacklisted = [ "graphite", "reims", "helios-6.sophia.grid5000.fr",
"helios-42.sophia.grid5000.fr", "helios-44.sophia.grid5000.fr",
"sol-21.sophia.grid5000.fr", "suno-3.sophia.grid5000.fr",
"grouille", "neowise", "pyxis", "drac", "servan", "troll", "yeti",
"sirius" ]
planning = get_planning()
slots = compute_slots(planning, 60*10, excluded_elements = blacklisted)
wanted = {'grid5000': 0}
start_date, end_date, resources = find_first_slot(slots, wanted)
actual_resources = { cluster: 1
for cluster, n_nodes in resources.items()
if cluster in get_g5k_clusters() and n_nodes > 0 }
logger.info("try to reserve " + str(actual_resources))
job_specs = get_jobs_specs(actual_resources, blacklisted)
jobid, sshkey = oargridsub(job_specs, start_date,
walltime = end_date - start_date)
if jobid:
try:
logger.info("wait job start")
wait_oargrid_job_start(jobid)
logger.info("get job nodes")
nodes = get_oargrid_job_nodes(jobid)
logger.info("got %i nodes" % (len(nodes),))
logger.info("run cpu performance settings check")
conn_parms = default_oarsh_oarcp_params.copy()
conn_parms['keyfile'] = sshkey
check = Remote("""\
find /sys/devices/system/cpu/ -name scaling_governor -exec cat {} \;
find /sys/devices/system/cpu -name thread_siblings_list -exec cat {} \;\\
| grep , >/dev/null \\
&& echo "hyperthreading on" || echo "hyperthreading off"
find /sys/devices/system/cpu -path */cpuidle/state2/time -exec cat {} \;\\
| grep -v 0 >/dev/null \\
&& echo "cstates on" || echo "cstates off"
if [ -e /sys/devices/system/cpu/cpufreq/boost ] ; then
grep 1 /sys/devices/system/cpu/cpufreq/boost >/dev/null\\
&& echo "turboboost on" || echo "turboboost off"
else
find /sys/devices/system/cpu -name scaling_available_frequencies\\
-exec awk \'{print $1 -$2}\' {} \; | grep 1000 >/dev/null\\
&& echo "turboboost on" || echo "turboboost off"
fi
""",
nodes,
connection_params = conn_parms)
for p in check.processes:
p.stdout_handlers.append("%s.out" % (p.host.address,))
check.run()
finally:
logger.info("deleting job")
oargriddel([jobid])
This code shows:
- how some clusters / sites or nodes can be blacklisted if needed.
- how to use
execo_g5k.config.default_oarsh_oarcp_paramsto connect to reserved nodes withoarsh. Explicitely setting the job key is mandatory unless you set$OAR_JOB_KEY_FILEin your environnement, or setg5k_configuration['oar_job_key_file'], as described in Grid5000 Charter and The perfect grid5000 connection configuration. - how to append a
execo.process.Processstdout_handlerwhich redirects output to a file. - how to take care of releasing the oargridjob with a try/finally block.
After running this code, you get in the current directory on localhost
a file for each remote hosts containing the scaling governors,
hyperthreading state, c-states state, turboboost state (easy to check
if they are all the same with cat * | sort -u)
Note that with this kind of code, there is still the possibility that the oar or oargrid reservation fails, since oar is not transactional, and someone can still reserve some resources between the moment we inquire the available resources and the moment we perform the reservation.
The planning module has several possibilities and modes, see its documentation for further reference.
Using Taktuk to scale to many remote hosts¶
This example shows how execo.action.Remote can be (almost)
transparently changed to execo.action.TaktukRemote to scale to huge
number of remote hosts. It uses the planning module, to try to reserve
80% of as much nodes as possible, immediately available for a 15
minutes job. It then opens as many ssh connexions to each host as the
host’s number or cpu cores, first using a execo.action.TaktukRemote,
then using execo.action.Remote, to compare performances. In each
remote connexion, it runs ping to send one ping packet to a
another random host of the reservation.
from execo import *
from execo_g5k import *
from execo_g5k.oar import oarsubgrid
import itertools, random, tempfile, shutil
logger.info("compute resources to reserve")
slots = compute_slots(get_planning(), 60*15)
wanted = { "grid5000": 0 }
start_date, end_date, resources = find_first_slot(slots, wanted)
actual_resources = distribute_hosts(resources, wanted, ratio = 0.8)
job_specs = get_jobs_specs(actual_resources)
logger.info("try to reserve " + str(actual_resources))
jobs = oarsubgrid(job_specs, start_date,
walltime = end_date - start_date)
if len(jobs) > 0:
try:
logger.info("wait jobs start")
for job in jobs: wait_oar_job_start(*job)
logger.info("get jobs nodes")
nodes = []
for job in jobs: nodes += get_oar_job_nodes(*job)
logger.info("got %i nodes" % (len(nodes),))
cores = []
nodes = sorted(nodes, key=get_host_cluster)
for cluster, cluster_nodes in itertools.groupby(nodes, key=get_host_cluster):
num_cores = get_host_attributes(get_cluster_hosts(cluster)[0])["architecture"]["nb_cores"]
for node in cluster_nodes:
cores += [ node ] * num_cores
logger.info("for a total of %i cores" % (len(cores),))
pingtargets = [ core.address for core in cores ]
random.shuffle(pingtargets)
ping1 = TaktukRemote("ping -c 1 {{pingtargets}}", cores)
ping2 = Remote("ping -c 1 {{pingtargets}}", cores)
logger.info("run taktukremote")
ping1.run()
logger.info("run remote (parallel ssh)")
ping2.run()
logger.info("summary:\n" + Report([ping1, ping2]).to_string())
finally:
logger.info("deleting jobs")
oardel(jobs)
Using a job type allow_classic_ssh solves a lot of connection
issues, there is no need to deal with oarsh.
Actually, what happens when running this code is that we can leverage
the huge scalabilty of Taktuk (we
have tested with more than 5000 concurrent remote connections),
whereas parallel ssh will show various limitations, in particular
the number of open file descriptors. In our tests run on grid5000
frontends, we can not run more than around 500 parallel ssh (this
could probably be increased on a node where you have root
permissions).
This example also show using execo_g5k.oar.oarsubgrid instead of
execo_g5k.oargrid.oargridsub. They are similar but oarsubgrid
bypasses oargrid and directly performs parallel oar submissions.
Compare ChainPut and parallel scp performances on many hosts on Grid5000¶
The following example shows how to use the execo.action.ChainPut
class (which also internally uses Taktuk) to perform optimized
transfers of big files to many hosts. It reserves 90% of the maximum
number of nodes immediately available on grid5000 for 15 minutes, and
broadcasts a generated random file of 50MB to all hosts both with
parallel scp and with ChainPut, to compare the performances. As
the parallel scp can be very resource hungry with a lot of remote
hosts, you should run this code from a compute node, not the frontend
(simply connect to a node with oarsub -I):
from execo import *
from execo_g5k import *
import tempfile, shutil
logger.info("compute resources to reserve")
slots = compute_slots(get_planning(), 60*15)
wanted = { "grid5000": 0 }
start_date, end_date, resources = find_first_slot(slots, wanted)
actual_resources = distribute_hosts(resources, wanted, ratio = 0.9)
job_specs = get_jobs_specs(actual_resources)
logger.info("try to reserve " + str(actual_resources))
jobid, sshkey = oargridsub(job_specs, start_date,
walltime = end_date - start_date)
if jobid:
try:
logger.info("generate random data")
Process("dd if=/dev/urandom of=randomdata bs=1M count=50").run()
logger.info("wait job start")
wait_oargrid_job_start(jobid)
logger.info("get job nodes")
nodes = get_oargrid_job_nodes(jobid)
logger.info("got %i nodes" % (len(nodes),))
conn_parms = default_oarsh_oarcp_params.copy()
tmpsshkey = tempfile.mktemp()
shutil.copy2(sshkey, tmpsshkey)
conn_parms['taktuk_options'] = ( "-s", "-S", "%s:%s" % (tmpsshkey, tmpsshkey))
conn_parms['keyfile'] = tmpsshkey
broadcast1 = ChainPut(nodes, ["randomdata"], "/tmp/",
connection_params = conn_parms)
broadcast2 = Put(nodes, ["randomdata"], "/tmp/",
connection_params = conn_parms)
logger.info("run chainput")
broadcast1.run()
logger.info("run parallel scp")
broadcast2.run()
logger.info("summary:\n" + Report([broadcast1, broadcast2]).to_string())
finally:
logger.info("deleting job")
oargriddel([jobid])
In this example, we use oarsh. One of the constraints imposed by
Taktuk is that any node of the connection tree must be able to
connect to any other. As the oargrid job key is only available on the
frontend on which the oargrid submission was done, we must propagate
this key to all nodes. This can be done with Taktuk option
-S. Alternatively, this is not needed if setting
$OAR_JOB_KEY_FILE in your environnement, or setting
g5k_configuration['oar_job_key_file'], as described in
Grid5000 Charter and
The perfect grid5000 connection configuration.
Analysis of TCP traffic Grid5000 hosts, using kadeploy¶
This example does not reserve the resources, instead it find all
currently running jobs, and tries to deploy to all nodes. It then
selects 2 nodes, connect to them as root, installs some packages, runs
tcp transfer between them, while, at the same time capturing the
network traffic, and finally it runs tcptrace on the captured
traffic:
from execo import *
from execo_g5k import *
logger.info("get currently running oar jobs")
jobs = get_current_oar_jobs(get_g5k_sites())
running_jobs = [ job for job in jobs if get_oar_job_info(*job).get("state") == "Running" ]
logger.info("currently running oar jobs " + str(running_jobs))
logger.info("get job nodes")
nodes = [ job_nodes for job in running_jobs for job_nodes in get_oar_job_nodes(*job) ]
logger.info("deploying %i nodes" % (len(nodes),))
deployed, undeployed = deploy(Deployment(nodes, env_name = "debian11-min"))
logger.info("%i deployed, %i undeployed" % (len(deployed), len(undeployed)))
if len(deployed) >= 2:
sources = list(deployed)[0:1]
dests = list(deployed)[1:2]
conn_params = {'user': 'root'}
conf_nodes = Remote(
"apt-get update ; apt-get -y install netcat-traditional tcpdump tcptrace",
sources + dests, conn_params)
send = Remote(
"dd if=/dev/zero bs=5000000 count=125 | nc -q 0 {{dests}} 6543",
sources, conn_params)
receive = Remote(
"nc -l -p 6543 > /dev/null",
dests, conn_params)
capture_if = [ [ adapter
for adapter in get_host_attributes(s)["network_adapters"]
if adapter.get("network_address") == s ][0]["device"]
for s in sources ]
capture = Remote(
"tcpdump -i {{capture_if}} -w /tmp/tmp.pcap host {{dests}} and tcp port 6543",
sources, conn_params)
tcptrace = Remote("tcptrace -Grlo1 /tmp/tmp.pcap", sources, conn_params)
for p in tcptrace.processes: p.stdout_handlers.append("%s.tcptrace.out" % (p.host.address,))
logger.info("configure nodes")
conf_nodes.run()
logger.info("start tcp receivers")
receive.start()
logger.info("start network captures")
capture.start()
logger.info("run tcp senders")
send.run()
receive.wait()
logger.info("stop network capture")
capture.kill().wait()
logger.info("run tcp traffic analysis")
tcptrace.run()
logger.info("stdout of senders:\n" + "\n".join([ p.host.address + ":\n" + p.stdout for p in send.processes ]))
logger.info("summary:\n" + Report([conf_nodes, receive, send, capture, tcptrace]).to_string())
else:
logger.info("not enough deployed nodes")
If this example is run several times, only the first time the nodes
are deployed, thanks to execo_g5k.deploy.deploy which runs a test
command on each deployed node to check if the node is already
deployed. This test command can be user customized or disabled, but
the default should work in most situations.
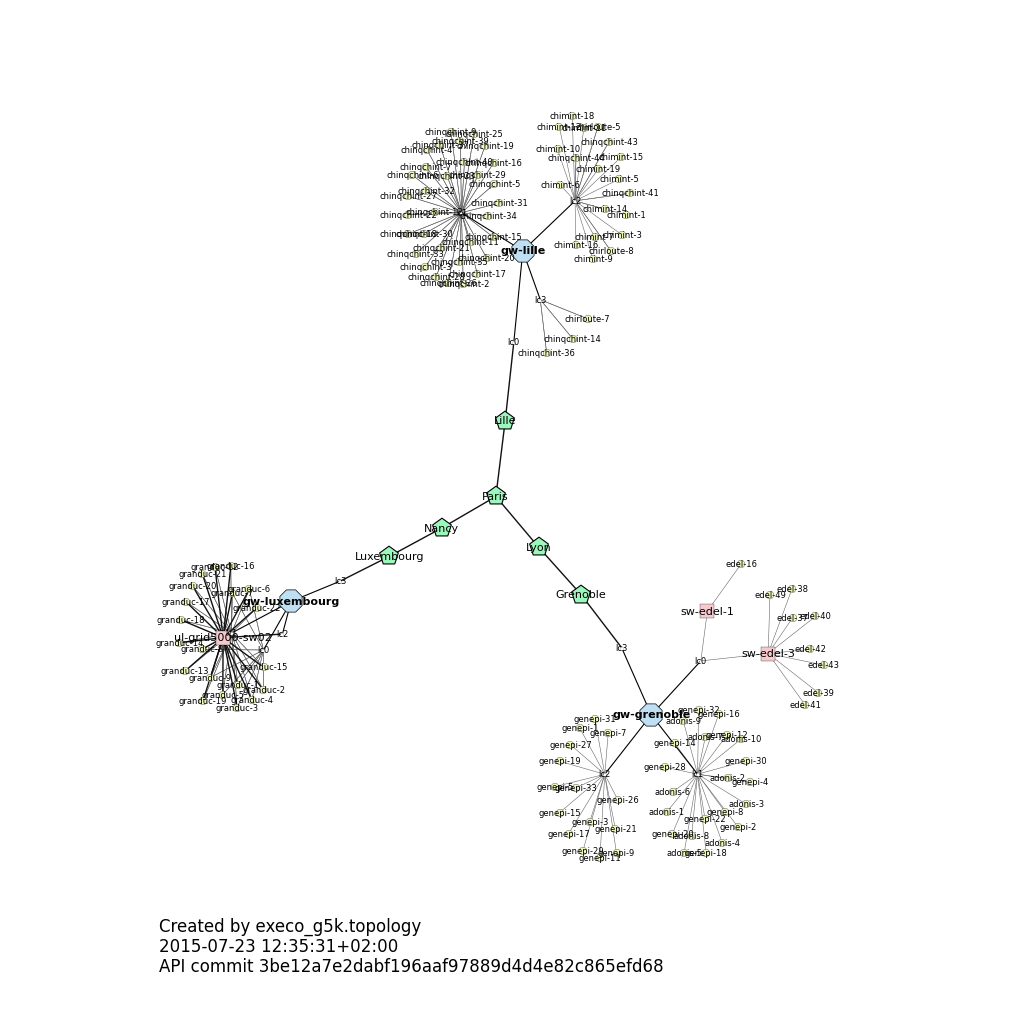
Playing with grid5000 network topology¶
Topology module offers an easy-to-use instance of a networkx.Multigraph whose
nodes are hosts, switchs, routers or renater POP and edges are
network links. Every elements has some attributes gathered from the
grid5000 API, like flops or bandwidth. The following example shows how to use
execo_g5k.topology to create the topological graph of an experiment and to
obtain a simple graphical representation using graphviz.
#!/usr/bin/env python
from execo_g5k.topology import g5k_graph, treemap
from execo.log import logger, style
from execo_g5k.oar import get_oar_job_nodes
from execo_g5k.utils import hosts_list
from networkx.algorithms.shortest_paths.generic import shortest_path
from execo_g5k.api_utils import get_host_shortname
from random import uniform
jobs = [(1696863, 'grenoble'), (1502558, 'lille'), (74715, 'luxembourg')]
logger.info('Retrieving hosts used for jobs %s',
', '.join([style.host(site) + ':' + style.emph(job_id)
for job_id, site in jobs]))
hosts = [get_host_shortname(h) for job_id, site in jobs
for h in get_oar_job_nodes(job_id, site)]
logger.info(hosts_list(hosts))
logger.info('Creating topological graph')
g = g5k_graph(elements=hosts)
i, j = int(uniform(1, len(hosts))), int(uniform(1, len(hosts)))
path = shortest_path(g, hosts[i], hosts[j])
logger.info('Communication between %s and %s go through '
'the following links: \n%s',
style.host(hosts[i]),
style.host(hosts[j]),
' -> '.join(path))
logger.info('Active links between nodes %s and %s are: \n%s',
style.host(path[0]),
style.host(path[1]),
{k: v for k, v in g.edge[path[0]][path[1]].items()
if v['active']})
logger.info('Generating graphical representation')
plt = treemap(g)
plt.show()
save = raw_input('Save the figure ? (y/[N]):') # use input instead of raw_input on python3
if save in ['y', 'Y', 'yes']:
outfile = 'g5k_xp_graph.png'
plt.savefig(outfile)
logger.info('Figure saved in %s', outfile)
It generates g5k_xp_graph.png:
Using execo_engine for experiment development¶
The execo_engine module provides tools that can be independently
used, or combined, to ease development of complex experiments.
Parameter sweeping¶
A common need is to explore the combinations of several
parameters. execo_engine.sweep.sweep defines a syntax to express
these parameters and generate the list of all parameters combinations
(the cartesian product). The syntax also allows explicitely
restricting the selection of some parameters combinations for some
values of another given parameter.
Checkpointed thread-safe and process-safe iterator¶
The execo_engine.sweep.ParamSweeper class allows creating
checkpointed, thread-safe, process-safe iterators over any
sequence. The iterated sequence may be the result of
execo_engine.sweep.sweep, or any sequence, provided that sequence
elements are hashable (if needed, the
execo_engine.sweep.HashableDict is provided, and it used in
sequences returned by execo_engine.sweep.sweep).
When instanciating a execo_engine.sweep.ParamSweeper, a storage
dictory is given, as well as the sequence to iterate. This class then
provides methods to iterate over the sequence, each elements moving
from states todo, inprogress, done, skipped. It is:
- checkpointed: iteration progress is reliably saved to disk in the storage directory
- thread-safe: threads can thread-safely share and use a single
execo_engine.sweep.ParamSweeperinstance - process-safe: several processes can safely instanciate
execo_engine.sweep.ParamSweepersharing the same storage directory, even on shared nfs storage. This allows, for example, having several independant jobs exploring a single parameter space, synchronizing only through independantexeco_engine.sweep.ParamSweeperinstances sharing the same storage.
Basic experiment lifecycle¶
The execo_engine.engine.Engine provides a canvas for experiment
lifecycle. It takes care of creating or reusing an experiment
directory, and convenient handling of logs. It provides absolutely no
fixed workflow. It can be subclassed to provide more specialized
engines, imposing particular workflows. To use
execo_engine.engine.Engine, you inherit a class from it, instanciate
it and call execo_engine.engine.Engine.start()
Puting it all together¶
This example show an experiment engine which measures the behavior of TCP congestion control mechanism with varying number of concurrent inter-site TCP connections (between 1 and 20) and different congestion control algorithms (cubic, the linux default, and reno). Each measure is repeated 3 times.
The engine class g5k_tcp_congestion is declared and inherits from
execo_engine.engine.Engine. Only the run is overridden, for a
straightforward experiment workflow:
- parameters are defined, and all parameter combinations computed lines 11 to 17.
- Needed resources are computed and reserved lines 20 to 43. Line 24
generates a
execo_g5k.planningresource description asking for one immediately available node on clusters on different sites, restricted to clusters whose nodes have a 1 Gbit/s ethernet interface. - If enough resources are available and grid job submission was successful, when nodes are available, they are deployed with image wheezy-x64-min, line 52. We need to deploy because we need root access on nodes to be able to change the linux TCP stack congestion algorithm.
- When deployment is finished, and enough nodes were deployed, the iperf package is installed on nodes.
- The actual parameter sweeping then starts line 58: for each parameter combination, the corresponding iperf server and client are run. Lines 71 to 77, iperf output is parsed.
- Lines 78 to 80, extracted results are appended to a yaml results file. Line 82, progress is checkpointed.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | # file: g5k_tcp_congestion.py
from execo import *
from execo_g5k import *
from execo_engine import *
import yaml, re, itertools
class g5k_tcp_congestion(Engine):
def run(self):
result_file = self.result_dir + "/results"
params = {
"num_flows": igeom(1, 20, 5),
"tcp_congestion_control": ["cubic", "reno"],
"repeat": list(range(0, 3)),
}
combs = sweep(params)
sweeper = ParamSweeper(self.result_dir + "/sweeper", combs)
logger.info("experiment plan: " + str(combs))
logger.info("compute resources to reserve")
planning = get_planning()
slots = compute_slots(planning, "01:00:00")
wanted = {'grid5000': 0}
start_date, end_date, resources = find_first_slot(slots, wanted)
actual_resources = dict(
list({ list(clusters)[0]:1 for site,clusters in
itertools.groupby(sorted([ cluster
for cluster, n_nodes in resources.items()
if cluster in get_g5k_clusters() and n_nodes > 0
and 1e9 ==
[adapter
for adapter in get_host_attributes(get_cluster_hosts(cluster)[0])["network_adapters"]
if adapter.get("network_address") ==
get_cluster_hosts(cluster)[0] + "." + get_cluster_site(cluster) + ".grid5000.fr"][0]["rate"]],
key = get_cluster_site),
get_cluster_site) }.items())[0:2])
if len(actual_resources) >= 2:
logger.info("try to reserve " + str(actual_resources))
job_specs = get_jobs_specs(actual_resources)
for job_spec in job_specs: job_spec[0].job_type = "deploy"
logger.info("submit job: " + str(job_specs))
jobid, sshkey = oargridsub(job_specs, start_date,
walltime = end_date - start_date)
if jobid:
try:
logger.info("wait job start")
wait_oargrid_job_start(jobid)
logger.info("get job nodes")
nodes = get_oargrid_job_nodes(jobid)
if len(nodes) != 2: raise Exception("not enough nodes")
logger.info("deploy %i nodes" % (len(nodes),))
deployed, undeployed = deploy(Deployment(nodes, env_name = "debian11-min"))
logger.info("%i deployed, %i undeployed" % (len(deployed), len(undeployed)))
if len(deployed) != 2: raise Exception("not enough deployed nodes")
logger.info("prepare nodes")
Remote("apt-get -y install iperf", nodes, connection_params = {"user": "root"}).run()
logger.info("start experiment campaign")
while len(sweeper.get_remaining()) > 0:
comb = sweeper.get_next()
destination = SshProcess("iperf -s", nodes[0],
connection_params = {"user": "root"})
sources = SshProcess("iperf -c %s -P %i -Z %s" % (nodes[0].address,
comb["num_flows"],
comb["tcp_congestion_control"]),
nodes[1], connection_params = {"user": "root"})
with destination.start():
sleep(2)
sources.run()
if comb["num_flows"] > 1:
pattern = "^\[SUM\].*\s(\d+(\.\d+)?) (\w?)bits/sec"
else:
pattern = "^\[\s*\d+\].*\s(\d+(\.\d+)?) (\w?)bits/sec"
bw_mo = re.search(pattern, sources.stdout, re.MULTILINE)
if bw_mo:
bw = float(bw_mo.group(1)) * {"": 1, "K": 1e3, "M": 1e6, "G": 1e9}[bw_mo.group(3)]
results = { "params": comb, "bw": bw }
with open(result_file, "a") as f:
yaml.dump([results], f, width = 72)
logger.info("comb : %s bw = %f bits/s" % (comb, bw))
sweeper.done(comb)
else:
logger.info("comb failed: %s" % (comb,))
logger.info("sources stdout:\n" + sources.stdout)
logger.info("sources stderr:\n" + sources.stderr)
logger.info("destination stdout:\n" + destination.stdout)
logger.info("destination stderr:\n" + destination.stderr)
sweeper.skip(comb)
finally:
logger.info("deleting job")
oargriddel([jobid])
else:
logger.info("not enough resources available: " + str(actual_resources))
if __name__ == "__main__":
engine = g5k_tcp_congestion()
engine.start()
|
This engine can be run in the following way:
$ python -i <path/to/g5k_tcp_congestion.py>
It can also be run in ipython to benefit from its interactive shell and debugger.
Using yaml for storing the results allows incrementally appending to
the file, and has the benefit of a human readable file. If there is an
error during the experiment (such as the end of the oargrid
reservation), the experiment can later be restarted in the same result
directory with option -C, continuing from where it stopped. It is
even possible to change the parameter combinations, only the yet
undone combinations will be done.
Below is an example showing how to load the results and draw a graph:
# file: g5k_tcp_congestion_process_results.py
import yaml, sys
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from scipy import stats
if __name__ == "__main__":
fname = sys.argv[1]
with open(fname, "r") as f:
results = yaml.load(f, Loader=yaml.UnsafeLoader)
arranged_results = {
tcp_congestion_control:
{ num_flows:
[ result["bw"]
for result in results
if (result["params"]["num_flows"] == num_flows
and result["params"]["tcp_congestion_control"] == tcp_congestion_control) ]
for num_flows in
[ result["params"]["num_flows"] for result in results ] }
for tcp_congestion_control in
[ result["params"]["tcp_congestion_control"] for result in results ] }
offset = -.18
for tcp_congestion_control in arranged_results:
plt.boxplot(list(arranged_results[tcp_congestion_control].values()),
positions = [ pos + offset for pos in arranged_results[tcp_congestion_control] ])
plt.plot(
sorted(arranged_results[tcp_congestion_control].keys()),
[ stats.scoreatpercentile(arranged_results[tcp_congestion_control][num_flows], 50)
for num_flows in sorted(arranged_results[tcp_congestion_control].keys())],
label = tcp_congestion_control, linewidth=0.5)
offset += .36
plt.xlim(0, max(arranged_results[tcp_congestion_control]) + 1)
#plt.xticks(arranged_results[tcp_congestion_control])
plt.legend(loc = 'lower right')
plt.xlabel('num flows')
plt.ylabel('bandwith bits/s')
plt.savefig("g5k_tcp_congestion.png")
It can be run this way:
$ python <path/to/g5k_tcp_congestion_process_results.py> <path_to_results_file>
It generates g5k_tcp_congestion.png:
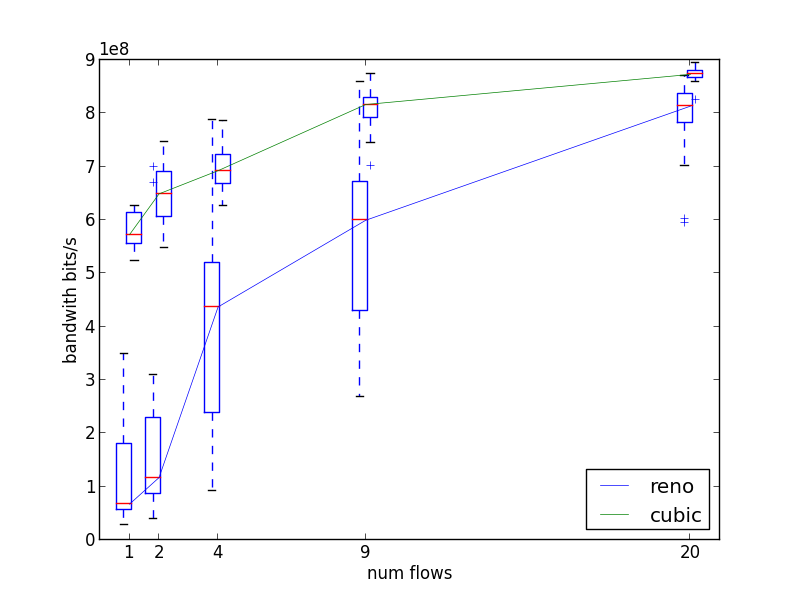
Note that this engine is simplified for the sake of demonstration purpose. For real experiment, for example, we should probably repeat measures more than 3 times to average the effect of cross-traffic on several measures. The figure above was actually drawn from 20 repetitions instead of 3.
More advanced usages¶
Use execo from outside Grid5000¶
If you use ssh with a proxycommand to connect directly to grid5000
servers or nodes from outside, as described in
https://www.grid5000.fr/mediawiki/index.php/SSH#Using_SSH_with_ssh_proxycommand_setup_to_access_hosts_inside_Grid.275000
the following configuration will allow to connect to grid5000 with
execo from outside. Note that
g5k_configuration['oar_job_key_file'] is indeed the path to the
key inside grid5000, because it is used at reservation time and oar
must have access to it. default_oarsh_oarcp_params['keyfile'] is
the path to the same key outside grid5000, because it is used to
connect to the nodes from outside:
import re
def host_rewrite_func(host):
return re.sub("\.grid5000\.fr$", ".g5k", host)
def frontend_rewrite_func(host):
return host + ".g5k"
g5k_configuration = {
'oar_job_key_file': 'path/to/ssh/key/inside/grid5000',
'default_frontend' : 'lyon',
'api_username' : 'g5k_username'
}
default_connection_params = {'host_rewrite_func': host_rewrite_func}
default_frontend_connection_params = {'host_rewrite_func': frontend_rewrite_func}
Bypass oarsh / oarcp¶
default_oarsh_oarcp_params = {
'user': "oar",
'keyfile': "path/to/ssh/key/outside/grid5000",
'port': 6667,
'ssh': 'ssh',
'scp': 'scp',
'taktuk_connector': 'ssh',
'host_rewrite_func': host_rewrite_func,
}
by directly connect to port 6667, it will save you from many problems such as high number of open pty as well as impossibility to kill oarsh / oarcp processes (due to it running sudoed)
Processes and actions factories¶
Processes and actions can be instanciated directly, but it can be more
convenient to use the factory methods execo.process.get_process
execo.action.get_remote, execo.action.get_fileput,
execo.action.get_fileget to instanciate the right objects:
execo.process.get_processinstanciates a Process or SshProcess depending on the presence of argument host different from None.execo.action.get_remote,execo.action.get_fileput,execo.action.get_filegetinstanciate ssh or taktuk based instances, depending on configuration variables “remote_tool”, “fileput_tool”, “fileget_tool”
